Projects
Ongoing Projects
- Development of a Genome Workbench for eukaryotic genomes using the biophysical fingerprints of various genomic elements
- Genome-wide identification of Phosphate Starvation Response-1-like binding (P1BS) element in the promoter region of genes in rice
Finished Projects
Biophysical Fingerprinting of eukaryotic genomic elements
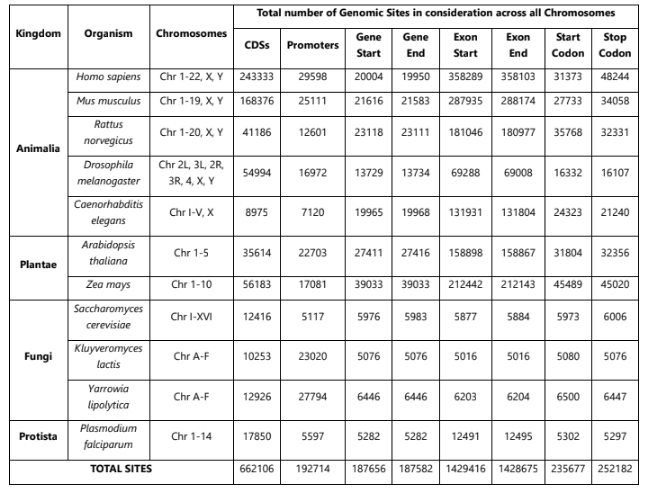
Abstract: DNA is a dynamic and intricate molecule, comprising a myriad of elements that orchestrate cellular functions. These elements are crucial in regulating gene expression, maintaining genome stability, and facilitating various cellular processes. Traditional profiling methods often fall short of providing functional genome annotations because they do not account for variations at sequence level across organisms. Our findings underscore the importance of comprehensive biophysical profiling in fully understanding DNA's complex regulatory mechanisms. Further, this knowledge lays the foundation for future methodologies that can exploit structural and energy parameters to annotate genomic elements with unprecedented precision and depth.
Development of an Intron-Exon Boundary Junction software using Physicochemical DNA features [MASTER'S DISSERTATION, IV SEMESTER, M.SC. BIOINFORMATICS]
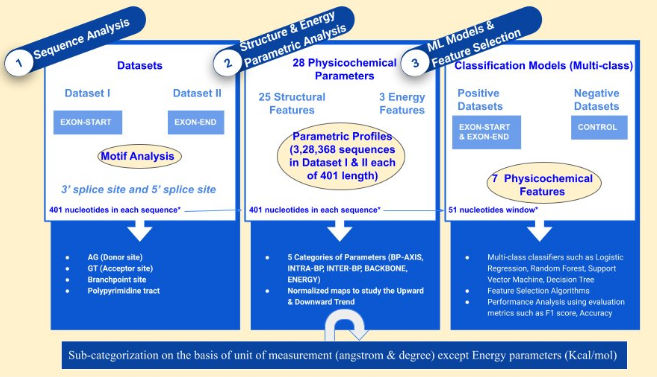
Abstract: Genomic sequences are the foundation of all living organisms, and their organization is crucial to understanding gene expression and function. Comprising four distinct units, namely Adenine (A), Thymine (T), Guanine (G), and Cytosine (C), the arrangement of these nucleotides has remained a significant challenge, underscoring the complexity of understanding their composition. Exons and introns are the key building blocks of genomic sequences, and their boundaries play a critical role in determining the final transcript and protein product. Various approaches have been employed to annotate this intricately orchestrated DNA sequence, yet a universally applicable method has remained elusive. Exons contain coding sequences while introns provide regulatory elements that control gene expression. In this project, we aim to develop an Intron-Exon boundaries prediction software using Physicochemical DNA features and their structural and energetic profiles to aid in the genome annotation process. The objectives of the project include a comprehensive literature review, visualization and interpretation of physicochemical parameters, implementation of various machine learning (ML) models for the development of software/tool, benchmarking, and handling of correlation and feature selection. The software will utilize a combination of literature review and physicochemical parameters to accurately predict intron-exon boundaries in DNA sequences and will be benchmarked against existing tools to evaluate its performance and contribution to genome annotation and understanding gene expression and function. Our forthcoming results will provide compelling evidence that DNA employs a distinct language tailored for eukaryotes. They will highlight the necessity of venturing beyond sequence-level analyses and delving into the physicochemical space to unlock the functional significance of DNA sequences.
In silico Gene-to-Drug Multitarget Inhibitor Search: Alzheimer’s Disease [MANUSCRIPT IN PREPARATION]
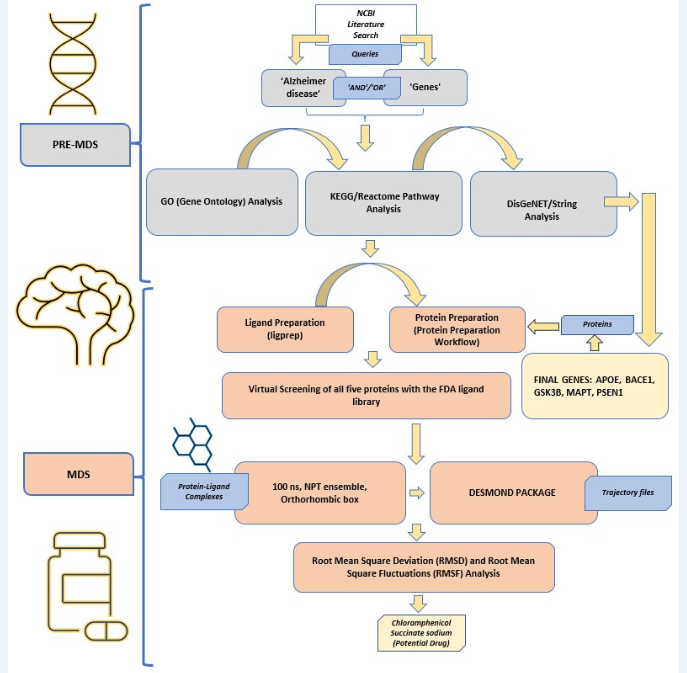
Abstract: Alzheimer's disease (AD) represents a progressive neurodegenerative disorder marked by pronounced declines in both memory and cognitive capacities. Pathologically, it manifests through the aggregation of extracellular amyloid β-peptides, intracellular hyperphosphorylated tau proteins, and perturbations in redox equilibrium. In recent years, there has been a notable surge, approximately tenfold, in research endeavors to elucidate effective therapeutic modalities to combat this debilitating affliction. An important advancement in Alzheimer's research has entailed exploring the intricate relationships among diverse genes and disease trajectories. Within this study, a group of genes was discerned utilizing a semi-automated literature-mining methodology at the National Center for Biotechnology Information (NCBI). The primary objective of this research is to implement a multi-targeted gene-to-drug strategy, establishing connections between these genes and a prospective drug candidate, thereby elucidating their direct involvement in the progression of AD. To corroborate the veracity of our results, we conducted simultaneous validation utilizing DisGeNET, which evaluated the association scores between the genes and the disease. Further, we utilized the Drug Bank library for potential drug repurposing, employing exhaustive gene-centric searches alongside high-throughput virtual screening, standard precision docking, and extra precise docking. Docking scores across all five proteins ranged from -5.730 kcal/mol to -9.269 kcal/mol for compounds in the FDA-human-approved library. Our study stands out for its meticulous consideration of multiple protein targets in Alzheimer's treatment and for conducting molecular mechanics-based and generalized surface area calculations, yielding outcomes indicating promising drug candidates. Furthermore, we conducted molecular dynamics simulations over 100 nanoseconds in a neutralized SPC water medium. The analytical framework incorporated root mean square deviation assessments, fluctuations, and simulated interactions among the protein-ligand complexes, water molecules, and proteins. Most complexes exhibited deviations of less than 3 Angstroms (Å), indicating their considerable stability. Fluctuations were minimal, with only specific residues demonstrating noteworthy variations alongside a significant network of interactions between the protein and ligand. Our analysis suggests Chloramphenicol (CP) succinate sodium as a potential candidate for Alzheimer's treatment, though rigorous experimental validation is imperative before clinical application.
A validatory analysis on the effects of BACE1 and regulatory neighbors in the progression of Alzheimer’s disease [MINOR PROJECT, III SEMESTER, M.SC. BIOINFORMATICS]
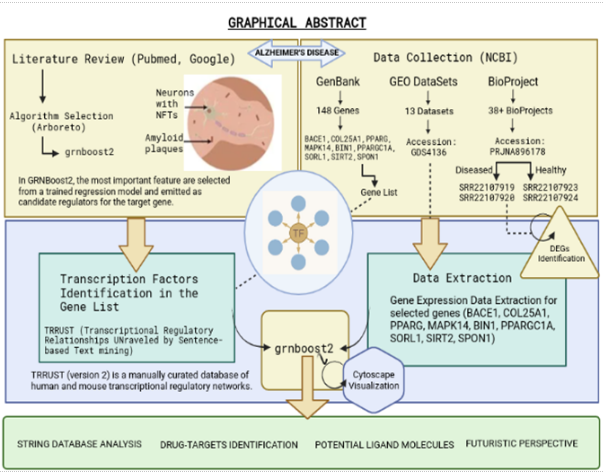
Abstract: Alzheimer’s disease is a progressive, terminal neurodegenerative disease that affects memory and other important mental functions. Common hallmarks of Alzheimer’s disease include the extracellular amyloid B-peptides aggregation and intracellular deposition of elevated levels of hyperphosphorylated tau protein along with a failure in redox homeostasis. In recent years, research has increased ten folds to find an effective treatment for this disease. The studies on substantial association of various genes with this disease’s progression is a significant milestone in Alzheimer’s research. In the last decade, the Alzforum has done a tremendous job in collecting and providing a list of all the involved genes based on published research. This study is based on a group of genes put together by a semi-automated literature mining approach at NCBI to analyze their inexplicit involvement in the progression of Alzheimer’s disease. To further our findings, we simultaneously conducted a DisGenet validation for BACE1 and other genes in the list based on gene-disease association scores. While most of them were listed with good scores, the others had no mention whatsoever. We also ran a differential expression analysis on using two controls and two diseased samples from Sequence Read Archive (SRA) database and identified seven out of the nine genes of interest among the Differentially Expressed Genes (DEGs). Moreover, with this study -- we aim to perform a validatory analysis on the effect of these genes at the expression of the BACE1 gene and construct a Gene Regulatory Network (GRN) for these genes with gene expression data. We screened the expression datasets for Alzheimer’s disease at National Center for Biotechnology Information (NCBI) using Gene Expression Omnibus (GEO) database with a semi-automated approach to extract the expression datasets for these genes and used it along with an alternate mining of Transcription Factors (TFs) among these genes using TRRUST (Transcriptional Regulatory Relationships Unraveled by Sentence-based Text-mining) database to generate the importance scores for every predicted interaction using Arboreto library in Python. We used the interaction information in source-sink form along with the scores to construct the network of these genes using Cytoscape. Furthermore, to establish a validatory ground for our initial hypothesis of involvement of these genes in the progression of Alzheimer’s disease, we provided insight into their effect on BACE1 expression.